Project Category
- Deep Learning
- Computer Vision
Description
You got a receipt – now you have to enter all data in your system. It’s okay for a few data but boring for large data. OCR is a traditional system used for a long to Digitize the document. This means we have an image and OCR will extract text from there. But getting raw text is not so interesting right.
Today, with Deep Learning you can do more with OCR. We can help you build OCR systems for Nepali Texts and Citizenship, Bills as well.
Use Cases
- Accounting and Receipt Management
- Citizenship Digitization
- Logistic Automation
- Any physical document to Digital
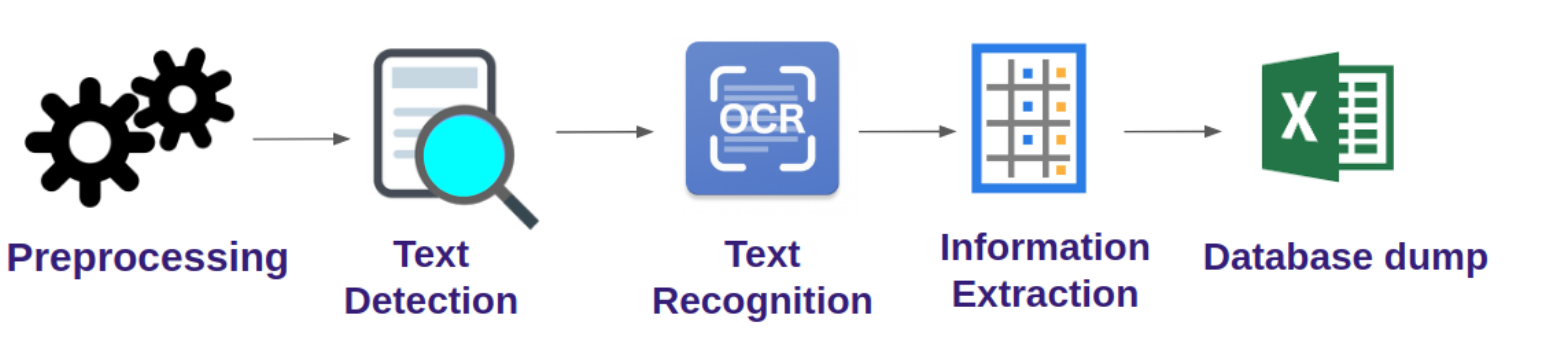
How we build the OCR in Nepal
1. Preprocess the data [ converting image to gray scale, blurring image and then adding threshold ]
– We need to gray scale as most OCR use black and white image
– We added threshold of 50 to convert any pixel below 50 to 0 and other to 255. It helps to capture word clearly
2. Sending the image to Tesseract OCR
– Using filters to separate the characters from the background
– Apply contour detection to recognize the filtered characters
– Use mage classification to identify the characters
3. Information Extraction
– OCR gives the raw text. We have to extract useful information from there.
– We used regex and other slicing for extracting information that we need.
Technology Stack
- Python
- Tesseract OCR